
L’Augmented Data Quality consiste nell’applicazione di funzionalità avanzate per automatizzare alcuni processi di qualità dei dati (DQ) con l’ausilio di “active metadata” e di tecnologie quali l’Artificial Intelligence e il Machine Learning.
Oggi gli specialisti dei dati affrontano sfide sempre più complesse: volumi in crescita, data source sempre più eterogenee e la necessità che il patrimonio informativo “AI-ready”. Queste esigenze hanno guidato Irion nello sviluppo di DAISY – Data Artificial Intelligence System. E dal 2025 siamo l’unica azienda italiana riconosciuta nel Magic Quadrant di Gartner per le Augmented Data Quality Solutions (scarica il report).
Ci sono molte attività di DQ che possono essere automatizzate come ad esempio la profilazione, il matching dei dati, la creazione automatica di link tra le entità, il merging, il cleansing, il monitoraggio, l’allineamento automatico tra le regole di controllo di business e quelle IT, la risoluzione delle anomalie o delle segnalazioni di scarsa qualità. Governare i dati significa creare e mantenere le condizioni che consentono di disporre delle informazioni necessarie quando servono, garantendone la completezza e l’accuratezza e quindi massimizzando i benefici derivanti dal loro impiego. Ma se le informazioni non sono affidabili? Se i dati sono errati, quali saranno le conseguenze per i processi decisionali?
L’Augmented Data Quality si pone l’obiettivo di garantire dati attendibili e di alta qualità, vitali alle organizzazioni, ma ha anche lo scopo di ridurre i compiti manuali legati alle pratiche di DQ, diminuendo l’intervento umano a favore dell’automatizzazione dei flussi di lavoro all’interno dei processi con un conseguente risparmio di tempo e risorse.
Come funziona l’Augmented Data Quality?
Le informazioni sono sempre state una risorsa fondamentale per le imprese. Ma se da una parte il loro valore è sempre più un fattore di vantaggio competitivo, dall’altra la crescita esponenziale dei dati disponibili rende complesso individuare quelle utili in un dato momento e per un certo scopo, capirne l’origine e la responsabilità, verificarne l’attendibilità e la freschezza, conoscere gli eventuali vincoli regolamentari e normativi cui deve conformarsi il loro impiego.
In questo ecosistema, secondo Gartner l’Augmented Data Quality è attivabile in tre “aree” specifiche:
- Discovery. Sono funzionalità sviluppate sfruttando le potenzialità degli active metadata e dei reference data in ambienti distribuiti con un elevato numero di data asset (interni ed esterni) sul cloud, in condizioni anche multicloud o on premise. Tecniche per trovare dove risiedono i dati, classificare ad esempio i dati sensibili ai fini della privacy intercettati automaticamente grazie alle caratteristiche degli stessi o rilevare correlazioni tra dati che risiedono in data source differenti.
- Suggestion. E’ possibile, ad esempio, partendo sempre dai metadati profilare i business term in modo da suggerire un arricchimento automatizzato del Data Catalog, presentare come papabili alcuni attributi collegabili alla specifica entità, consigliare delle azioni di remediation al fine di correggere eventuali anomalie rilevate imparando di volta in volta dal comportamento degli users, indicare eventuali legami di lineage tra le entità di processo di business, proporre regole di controllo dei dati o sfruttare le informazioni deducibili dalla lettura degli application log.
- Automation. Molte pratiche comuni possono essere automatizzate come la correzione dei casi anomali con una confidenza sopra una certa soglia, l’applicazione di regole a certe tipologie di dati come quelli sensibili ai fini della privacy. Dotarsi di un motore di verbalizzazione può ad esempio ridurre drasticamente il tempo necessario per scrivere una documentazione aggiornata nel rispetto delle regole e delle procedure di controllo garantendo la coerenza tra Business e Technical rules in caso di ispezione.
Per rispondere a specifiche esigenze operative, DAISY introduce funzionalità di assistenza intelligente, come il Copilot Pipeline & Rule Wizard che riduce drasticamente i tempi di configurazione dei controlli. E la Smart Data Discovery supporta gli utenti nell’individuazione automatica di anomalie o relazioni inattese nei dataset, anche su grandi volumi. DAISY permette anche l’Automatic Vertical Lineage, per visualizzare come le modifiche ai dati influenzano processi e output, particolarmente utile nei processi di audit e compliance.
Ma entriamo maggiormente nel dettaglio con un esempio pratico, sempre Gartner ci evidenzia nello schema sottostante, come in un tipico processo di data quality è possibile per ogni fase individuare alcune “azioni” automatizzabili.
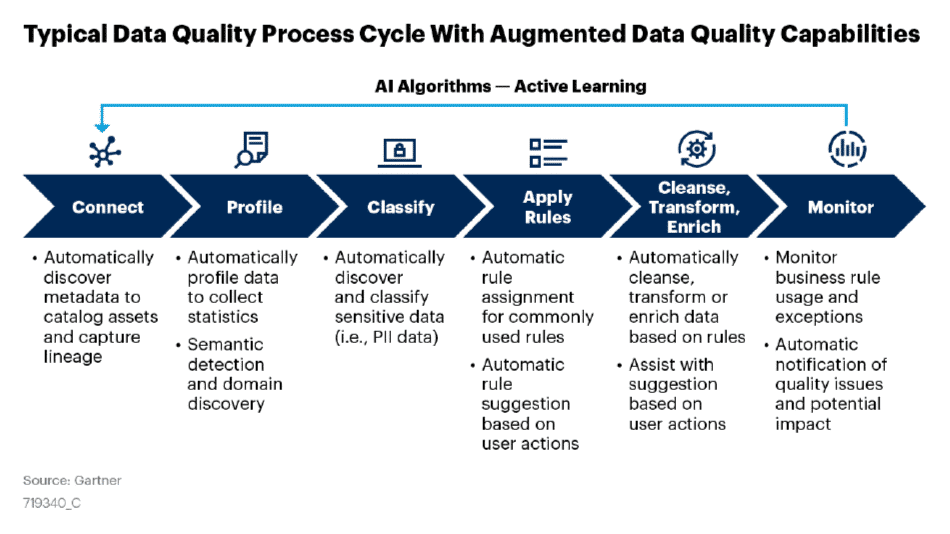
Tutti questi assunti dimostrano che oltre ad un efficace strumento di data Quality avanzato in grado di verificare, attraverso l’esecuzione di controlli, la rispondenza dei dati ad una serie di requisiti tecnici e di business è necessario dotarsi un tool di Data Governance ovvero di un sistema di gestione dei metadati, che gestisca una “carta di identità” delle informazioni aziendali, comprendente tutte le entità di business (semantica, ownership, processi impattati, regole di qualità e retention…) e tecniche (formati, applicazioni originanti, controlli fisici…) che li caratterizzano, i relativi attributi e le mutue relazioni. Queste due componenti sono strettamente interconnesse, così come data quality e data governance sono due discipline inscindibili, che si sostengono vicendevolmente. La piattaforma EDM di Irion offre in un unico ambiente integrato tutti gli strumenti per sostenere sistemi di data quality e data governance flessibili, scalabili, proporzionati al contesto, a prova di futuro.
Queste innovazioni nascono per rispondere a esigenze concrete del mercato, sempre più orientato a ottenere dati pronti per l’AI e il decision-making.
Porta i tuoi dati nell’era dell’AI: scopri come Irion ti supporta con l’Augmented Data Quality




